* 2024.04 ~ 2024.05 (6주) 실전 프로젝트 한 것 총 정리
✅ 실전 프로젝트 개요
이번 프로젝트는 BE/FE 로 나뉘어 각자의 역할에 맞는 기능을 구현하는 실제 서비스팀의 업무와 유사하게 진행하였습니다. 또한, 이번의 프로젝트에서는 Back-end Leader로서 프로젝트가 바른 방향으로 진행되고, 일정(6주) 안에 핵심 기능을 구현할 수 있도록 노력하였습니다.
팀 구성은 Web Design 1명, FE 2명 BE 4명으로 구성되었고 BE 개발자는 다음과 같이 역할 분담을 하였습니다.
팀원1 : 여행 후기 CRUD, 이미지 처리, 좋아요, 스크랩, 모니터링 툴 도입(Grafana, Promethus)
팀원2 : 여행 플랜 CRUD, 투표 기능 , CI/CD, 좋아요, 스크랩
팀원3 : 로그인, 회원가입, 알림 기능
본인 : 랭킹 기능, 검색 기능, 추천 기능, 성능 분석 , 좋아요, 스크랩, 테스트 툴 도입(JMeter, Java Faker)
✅ 실전 프로젝트 소개
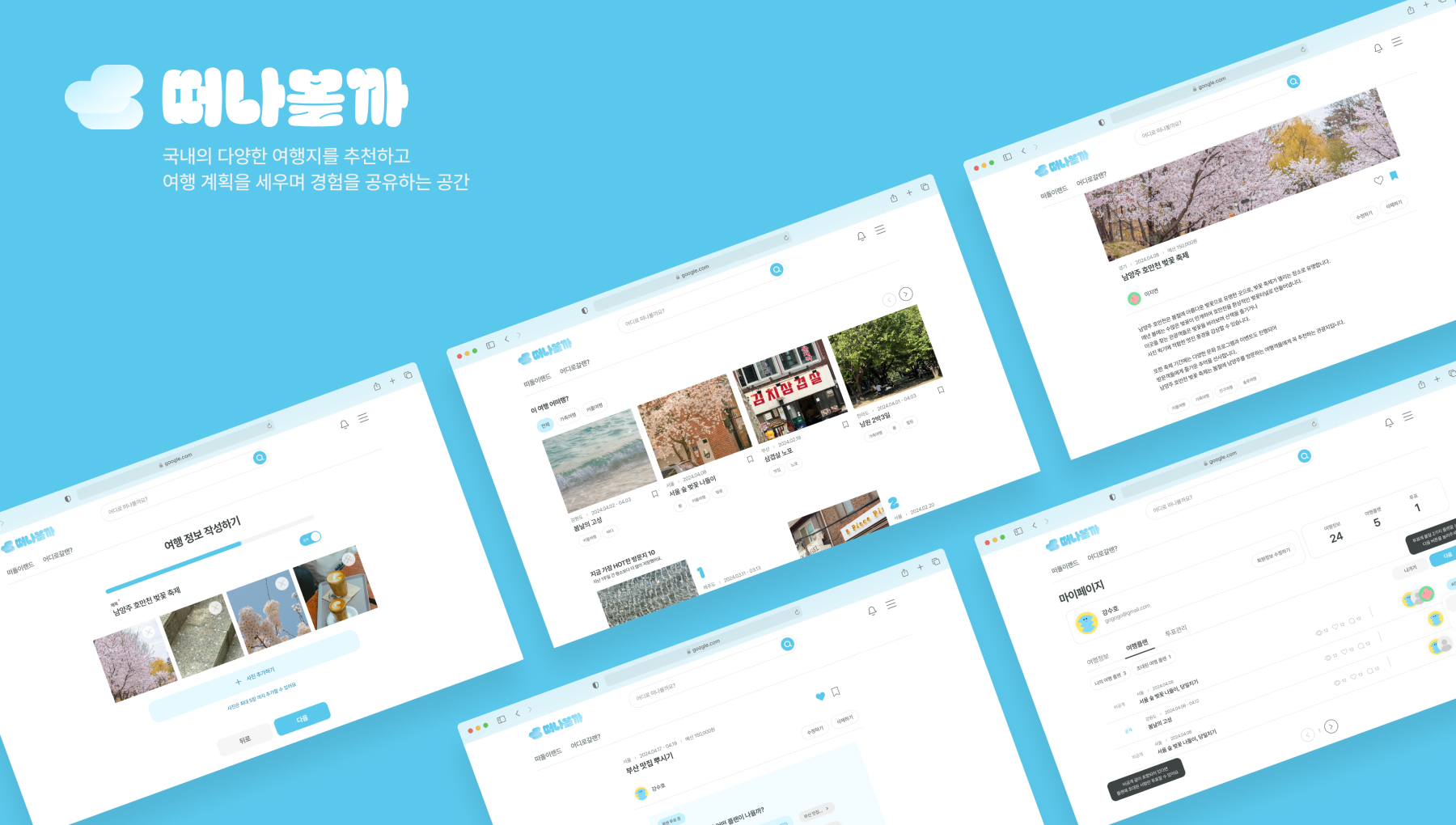
어떻게 여행할지 계획이 힘들다구요?! 플랜을 여러개 작성해서 투표하고 다녀오세요~!
물론?! 후기도 남기면 함께 여행가는 즐거움을 느낄 수 있습니다!
* 빠르고 쉬운 플랜 및 후기 작성을 바탕으로 맞춤 여행 플랜 및 후기 정보를 제공합니다.
GitHub - TravelLand/Travly_BE: 떠나볼까 BE repository
떠나볼까 BE repository. Contribute to TravelLand/Travly_BE development by creating an account on GitHub.
github.com
✓ 주요 기능
1. 여행 후기
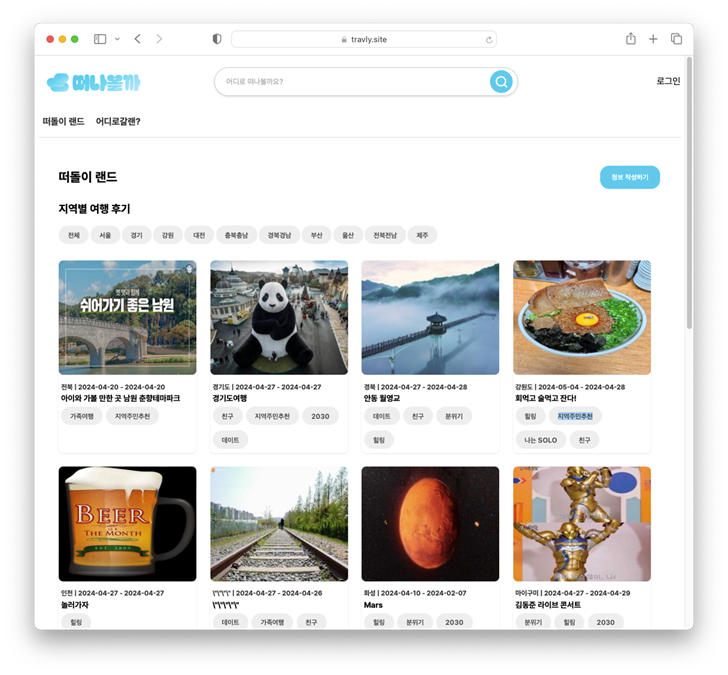
- 새로운 여행 목적지를 발견할 수 있도록 도와줍니다.
- 국내 다양한 여행지를 추천하고 다양한 경험을 공유하는 공간
2. 여행 플랜 및 투표
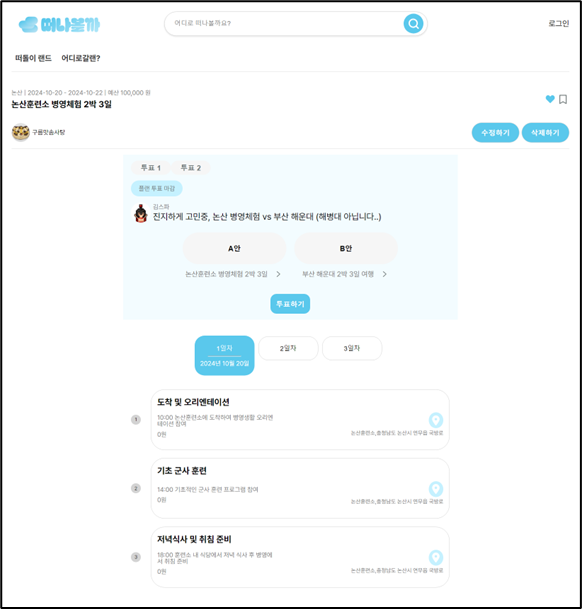
- 개인 또는 친구들과 함께 통하여 계획을 세워 볼 수 있습니다.
- 만약 일정이 여러개 라면 투표를 통하여 의견을 수렴 할 수 있습니다.
- 새로운 여행지에 대한 계획을 하고, 먼저 다녀온 사람들의 의견을 들어볼 수 있는 공간
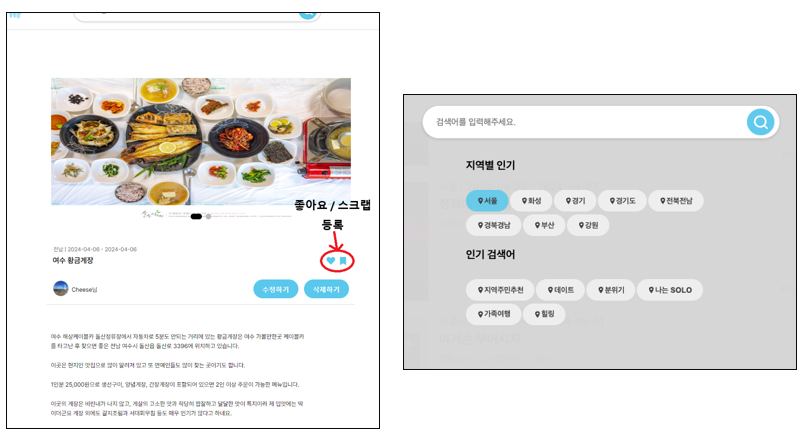
3. 기타 편의 기능
- 검색, 좋아요, 스크랩, 인기검색어 추천 기능을 제공합니다.
✅ 시스템 아키텍쳐 설계 및 기술 선택 과정
시스템 아키텍쳐는 서비스의 규모를 확장 할 수 있는 형태로 설계하였고, 기술 스택은 실무에서 많이 사용하는 가, 이전에 교육 받은 내용에 포함되는 가, 레퍼런스 자료가 많은 가를 기본적으로 고려하면서 선택하였다.
또한, 요구하는 기능에 적합한 기술을 선택하기 위해 노력하였고, 사이드 이펙트를 최소화 하기 위해서 Spring-boot에 일치하는 버전 사용 및 무분별한 인프라 도입은 지양 하였다.
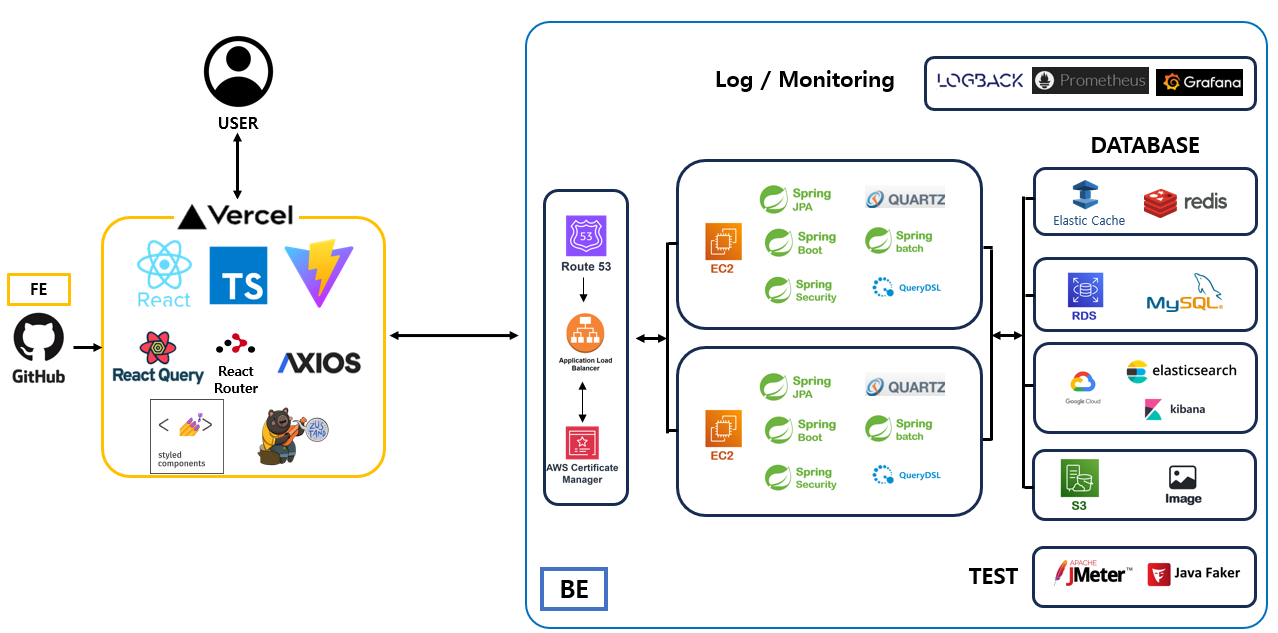
✓ 아키텍쳐 설계 과정
- Spring-boot로 개발을 진행함으로 MVC 패턴과 OOP 위주 설계
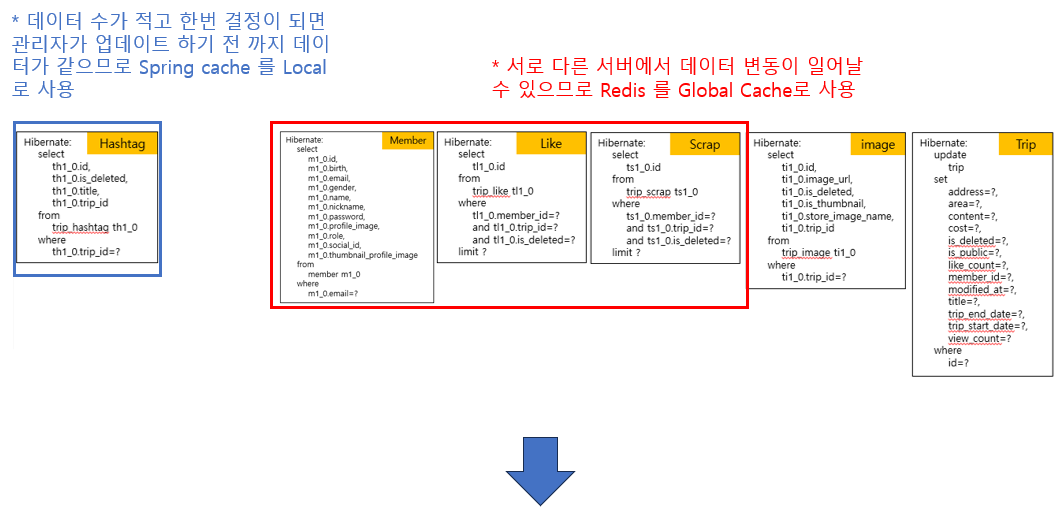
- OOP 를 위해서 RDBMS를 선택(MySQL)
- RDBMS 는 Scale out 에 상대적으로 고비용이 든다는 단점이 존재함으로 별도의 Cache를 지정하고(Redis) 관리하여 RDB의 부하를 줄임
- Elasticsearch 다양한 한글 검색 기능과 RDB의 부하를 줄이기 위해 도입
-이미지 데이터 저장용 S3 도입
- DB 와 서버는 추수 scale out이나 대체에 용이 하도록 최대한 결합도를 낮추어 연결
✓ 기술 선택 과정
1. IntelliJ VS Eclipse
- 사용 편의성 고려
- 백엔드 팀원 모두 익숙한 tool 선택
- 제공 받은 기간제 유료 버전 사용
2. AWS VS GCP VS NCP
- 레퍼런스가 많음
- 다양한 인프라를 함께 제공
- 높은 안정성
3. Redis VS memcached
- Global cache
- 다양한 옵션을 지정하여 디스크에 저장가능
- 다양한 자료구조 제공
4. MySQL VS Oracle
- 레퍼런스가 많음
- 오픈소스
- 지속적인 버전업으로 성능개선
5. Elasticsearch VS MySQL Full text index
- 역인덱스 구조로 검색 효율화
- 다양한 한글 관련 플러그인 지원
✅ Trouble Shooting
트러블 슈팅의 대상은 평소 문제점이 일어날 수 있는 부분을 위주로 확인하였고, 실제로 성능 저하가 일어나는 부분의 원인을 분석하였다.
원인 분석 후, 해당하는 문제점을 해결하기 위한 새로운 기술이나, 코드 구현 등 우리 서비스에 적합한 방식으로 해결을 하기위해 노력하였다.
또한, 과도하게 문제점을 찾아내어 오버 엔지니어링 하는 실수를 방지하기 위해서 지속적으로 서비스의 예상 범위( 게시글 50만건, 유저 10만명, 동시 요청수 10 )을 고려한 Test를 수행하면서 트러블 슈팅을 진행하였다.
✓ 조회 성능 개선
1. 페이징 처리 ( Cursor 기반 및 쿼리문 개선)
Offset 기반 페이징 처리는 Offset 의 숫자가 커질 수록 해당 위치를 찾기 위하여 카운팅을 하므로 불필요한 집계가 일어나는 현상이 존재한다. 그러므로 Cursor (이전의 위치를 기억하고 있다가 적용하므로 카운팅 X ) 기반 페이징 처리로 리펙토링하는 작업을 수행하였다.
또한, JPA를 기본 문법 사용하여 페이징 처리를 하였는데 불필요하게 한 컬럼에 대한 모든 field 정보를 load 하므로 메모리 낭비를 초래하므로 QueryDSL을 사용하여 필요한 field 정보만 가져와 DTO로 반환하도록 수정하였다.
- 기존의 Paging 처리 문제점
- offset 기반이기 때문에 뒷쪽의 페이지를 조회하면 시작부터 해당 위치까지 카운트를 실행
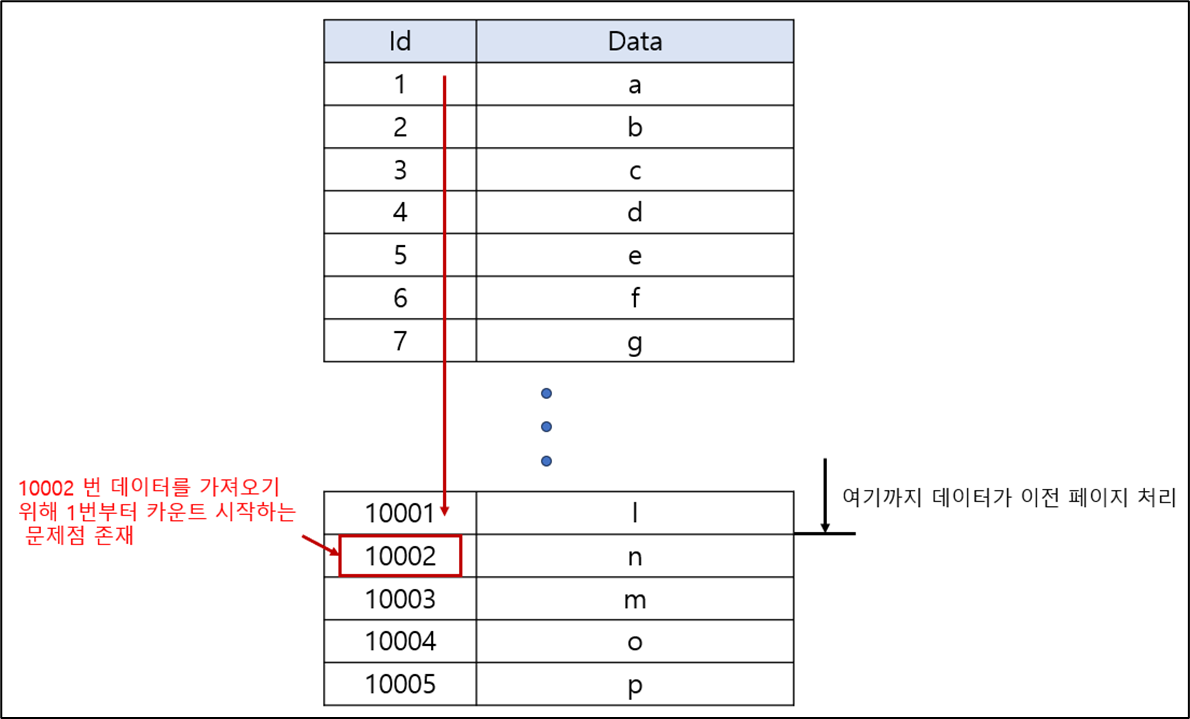
- JPA 기본 쿼리 사용으로 불필요한 데이터 모두 SELECT 되는 문제 존재
- 해결 방법
- cursor 기반 페이징 처리 방식으로 수정
- QueryDSL을 사용하여 필요한 데이터만 조회
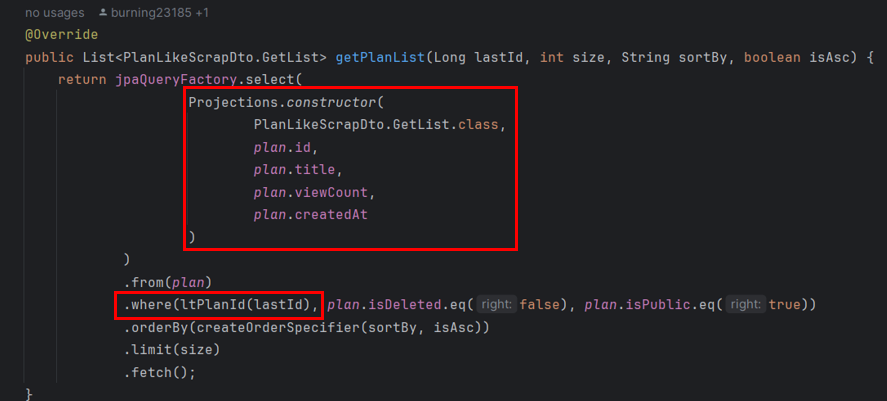
- 페이징 처리 문제 개선 결과 (게시글 50만건 기준)
- 페이지 수가 늘어나면 늘어날 수록 성능 개선 효과가 커짐
2. 상세 페이지 조회 ( 상세 페이지 조회시 관련 쿼리문 다수 발생 )
상세 페이지 조회 시, 관계 테이블 조회로 인하여 부가적인 SELECT 문이 5개가 더 추가로 발생한다. 이 현상으로 "속도 저하가 발생하지 않을까"라는 우려가 있었고 실제로 얼만큼의 속도저하가 일어나는지 확인하기 위해서 동시 요청 수 1000건을 기준으로 10번 반복 Test 를 진행하였다.
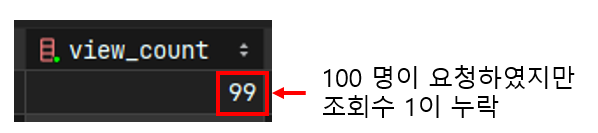
Test 진행 후, 10000건에 대한 처리 속도가 매우 빠르게 나타났다. 그래서 실제로 10000건이 조회 되었는지 조회수를 확인하는 과정에서 동시성 문제를 발견하였다. 조회수가 10000건으로 예상하였는데 실제로는 9982건으로 조회수 누락이 발생한 것이다. race 현상이 발생하여 업데이트 되지 못한 데이터를 다른 요청에서 받은 후, 업데이트 한 결과에 다시 덮어쓰기가 되어 카운트 수가 줄어든 것이다.
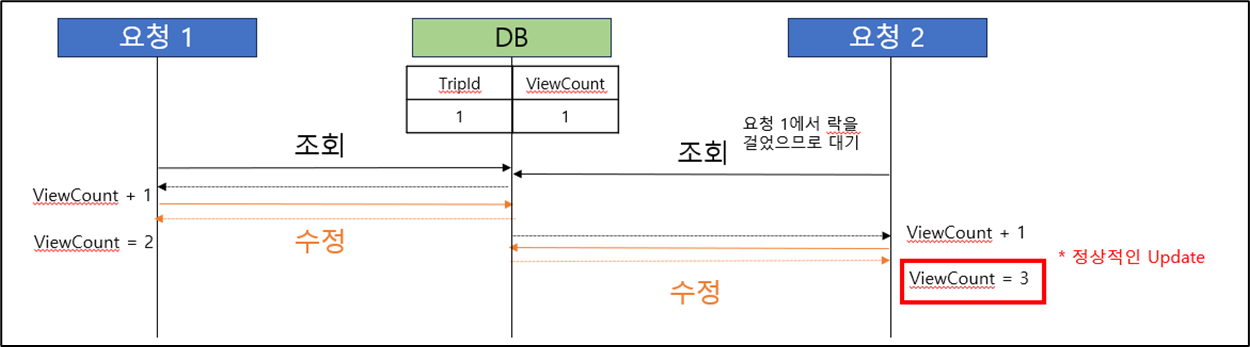
이 현상을 해결하기 위해서, 최초로 낙관적락과 비관적락을 고려하였다. 충돌이 일어날 것을 예상하였기 때문에 낙관적 락보다는 성능이 떨어지더라도 비관적 락을 거는 것이 더 합당하다고 판단하여 비관적 락 방식을 적용하여 해결하였다. 그리고 비관적 락으로 인하여 추가적인 사이드 이펙트가 어떤것이 있을지 조사하였고 관계 테이블이 많은 경우 서로 다른 리소스를 점유하면서 데드락 현상이 발생할 수 있다는 정보를 얻었다.
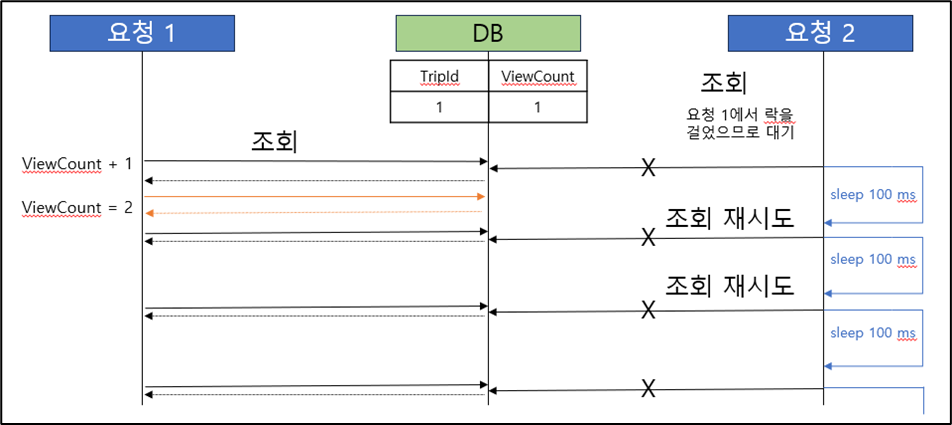
그래서 다른 해결 방법에 대해서 조사하였고, 두번째 해결 방법으로 사용하고 있는 Redis를 이용하여 (Spring-data-redis) 해결하는 방법을 검토하였다. 이 방법 역시 동시성 문제는 발생하지 않았지만 스핀락 방식에서 오는 또다른 문제점 (무한 대기 현상) 이 존재하였다. 그래서 통상적으로 사용하는 방법에는 어떠한 것이 있을까 조사한 결과 분산락을 이용하면 해결할 수 있다는 정보를 습득할 수 있엇다.
분산락 방식은 Redisson 이라는 의존성을 추가하여 구현할 수 있었는데, 해당 방법을 사용하기 위해서는 새로운 의존성을 도입 하여야 하고 추후, 구조를 변경해야 할 수 도있는 리스크를 가지고 있었다. 그래서 해당 방식을 적용하기 위해 시간을 소요한다면 짧은 프로젝트 기간 6주 중 기획 및 설계에 1주, 안정화 및 유저 피드벡 1주를 제외한다면 또다른 중요한 기능을 구현할 수 없다는 판단이 들었다.
그래서 "어느 정도의 요청이 들어왔을 때 동시성 문제가 일어나는 가"를 확인하기 위해서 Test 를 진행하였고, 동시 요청 100건 부터 발생하기 시작한다는 것을 발견하였다. 현재 설계한 서비스의 규모상 같은 글을 100명이서 동시에 클릭하는 경우는 거의 없다고 판단되었고 발생하더라도 조회수 1-2 정도만 누락된다는 점에서 상대적으로 피해가 크지 않다는 것도 고려되었다.
최종적으로, 조회수 관련 동시성 문제는 문제되는 상황을 인지하고 서비스의 규모가 커질 때, 개선하도록 결정하였다. 그리고 원래의 인식되었던 문제 ( 쿼리문이 5개 발생 )는 크게 속도 저하를 발생시키진 않았지만, 비효율적이라고 판단하였고 Cache를 이용하여서 조회의 성능을 개선하였다.
- 기존의 Detail page 조회시 문제점
- 관련 쿼리문이 여러개 발생
- 상세 페이지 진입시 마다 중복 체크 기능이 없어 무분별한 DB 업데이트 발생(조회수 증가)

1 번 조회시 발생하는 쿼리문
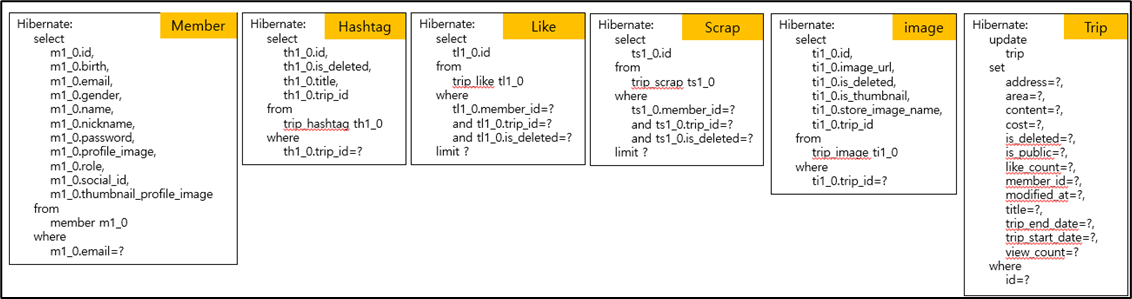
- 기존의 처리방법의 속도를 측정하기 위해 TEST 하는 중 새로운 문제점(동시성) 발견
- 100명이 조회 요청을 하였을 때, 1개의 데이터 누락(덮어쓰기)이 발생
- 첫 번째 해결 시도 (비관적 락 설정 - 충돌이 발생할 것을 예상했기 때문)
* Shared Lock : 트랜잭션이 데이터를 조회만 할 수 있도록 지정하는 락 (조회수를 업데이트 해야하기 때문에 사용 불가)
* Exclusive Lock : 데이터를 변경할 때 사용하는 락, read/write를 모두 막음 (데드락 발생 가능 하기 때문에 사용 불가)
* 낙관적 락 : 충돌이 일어날 경우 예외처리 (충돌이 빈번하게 일어나는 상황에는 계속 rollback 이 진행되므로 사용 불가)
- 첫 번째 해결 방법 문제점 발견 ( 데드락 - 관계 테이블이 많기 때문 )
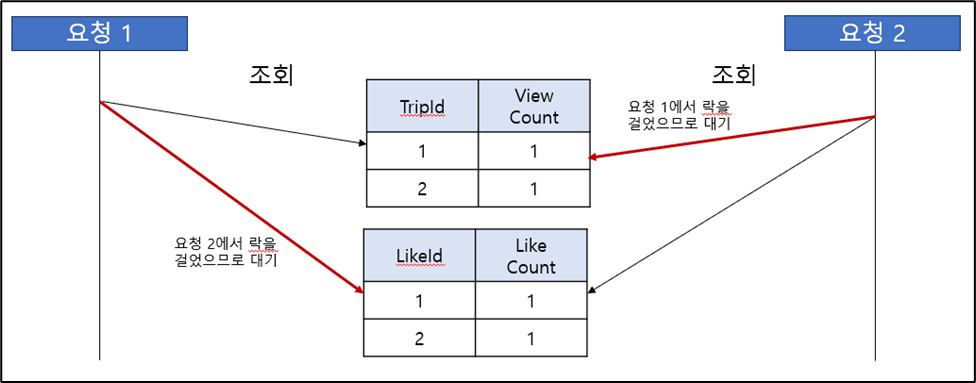
- 두 번째 해결 시도 ( Spring Data Redis - Lettuce Spin Lock 방식_Default )
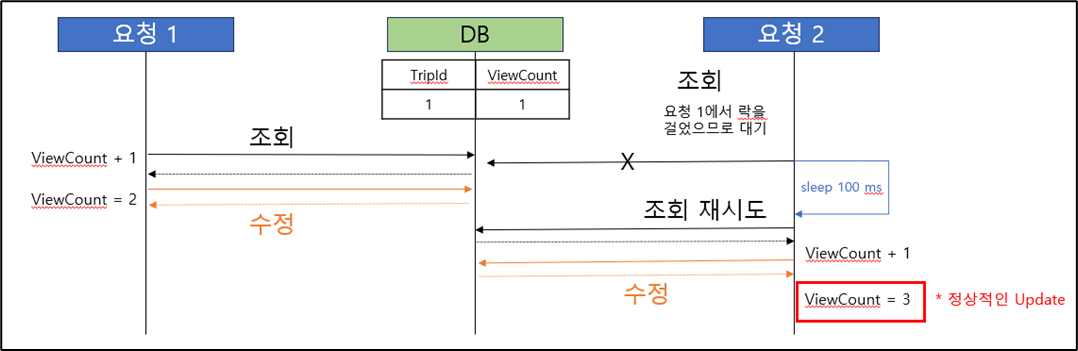
- 두 번째 해결 방법 문제점 발견 ( Redis 과부하 및 무한 대기 발생 가능 )
- 세 번째 해결 시도 ( Redisson - Distributed Lock 방식 )
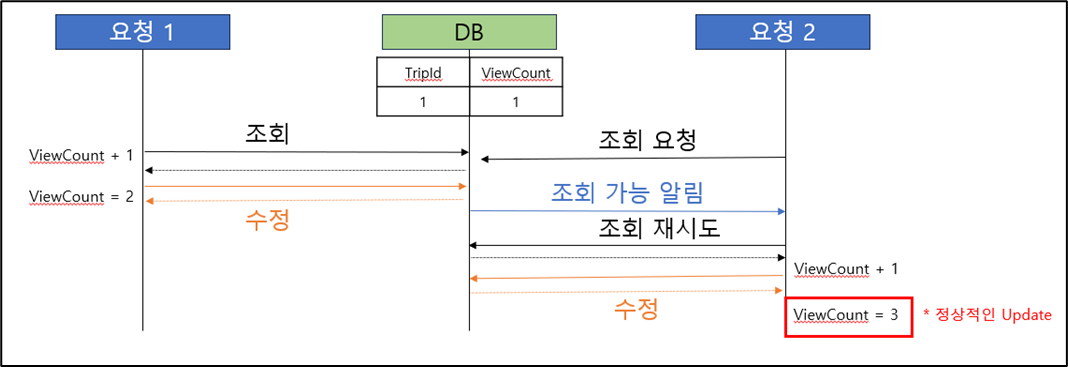
- 세 번째 해결 방법 문제점 (조회수는 상대적으로 중요 정보가 아님, Redisson 도입으로 인한 사이드 이펙트 발생 가능)
- 최종 해결 방법 선택 ( JPA 사용 및 Spring Data Redis 를 사용한 캐싱 처리 )
* Spring Data Redis : 이미 사용중인 의존성, 별도의 설정을 통하여 무한 대기 방지
* 캐쉬 전략 : Read through, Write through 전략을 사용하여 데이터의 일치성 보장 (추후 Write around로 리펙토링 검토)


- Detail page 조회 개선 결과

3. Main 페이지 조회 ( Rank Top 10 기능으로 인해 조회마다 집계 함수 사용 )
Main 페이지 조회시 Rank Top10 을 표기하기 위해서 요청이 발생할 때마다 조회수를 집계하는 문제가 있었다. 그러므로 게시글 수가 적을때는 관계없지만 게시글이 늘어날 경우 속도저하를 일으킬 수 있다고 판단하였다. 그래서 Test를 진행하여 얼마만큼의 속도 저하가 일어나는 지 확인하였다.
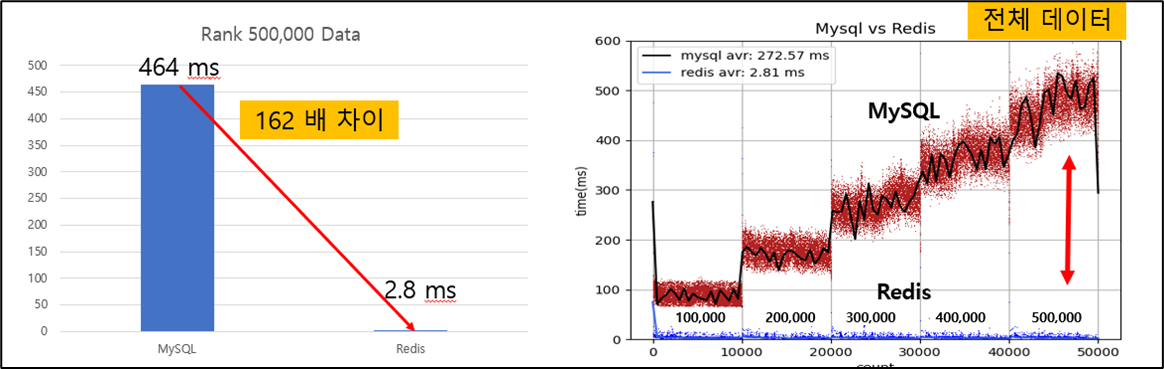
게시글이 30만건 이상이 될때 부터 요청수가 많아진다면 DB에서 병목현상이 발생할 수 도 있다는 결과를 얻을 수 있었다. 이를 개선하기 위해서 Redis 의 Sorted Set 자료 구조를 이용하여 데이터를 입력할 때, 정렬하면서 저장을 하고 조회시 바로 10개를 호출하는 방식으로 개선을 진행하였다.
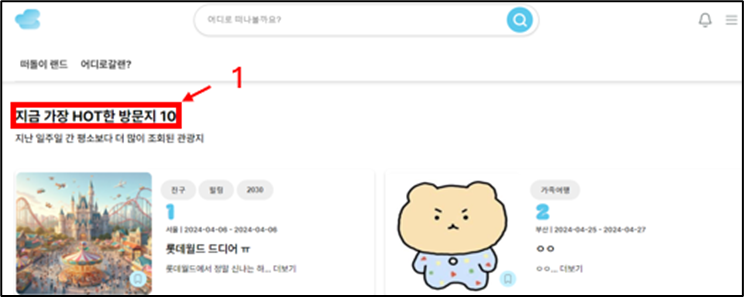
- 기존의 Rank 집계 함수 사용시 문제점
- 데이터가 증가할 경우 DB 병목 현상 발생
- Main Page로 인하여 다른 기능 까지 장애 발생
- 해결 방법
- Redis 의 Sorted Sets 자료 구조 사용
- Main 페이지 조회 개선 결과
✓ 검색 성능 및 기능 개선 ( Elasticsearch )
1. 검색 성능 개선
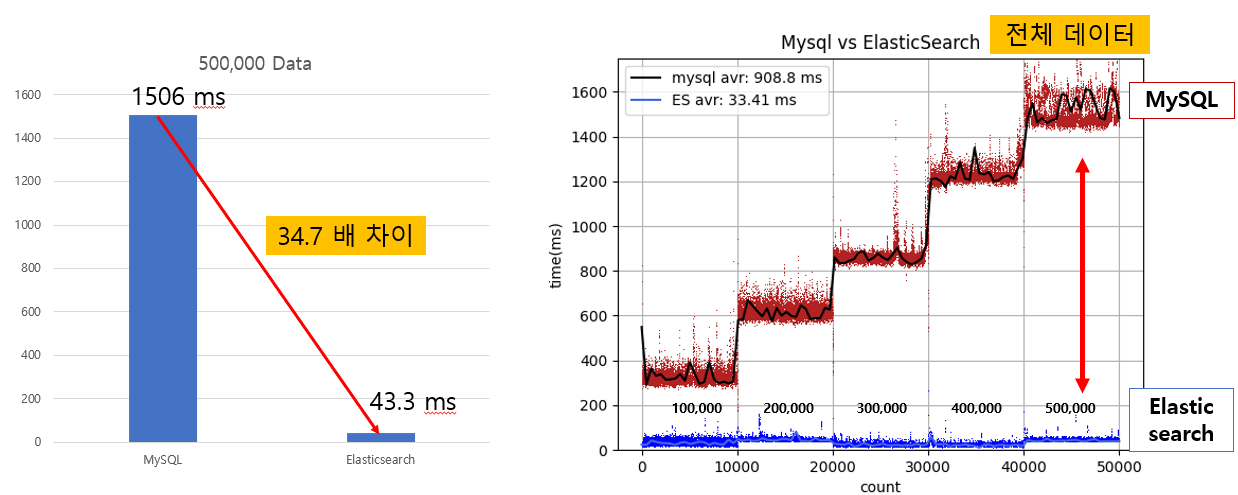
초기 검색 기능을 구현할 때, 간단하게 Like 문을 사용하여서 개발하였다. 하지만 이방식은 속도 저하를 가져오고 다양한 검색을 지원하기 위해서는 더욱 큰 시간이 소요된다는 것으로 판단하였다. 그래서 일반적으로 검색에 사용하는 방법에 대해서 조사하였고 Full Text Index 방식과 Elasticsearch를 사용하는 방법을 검토하게 되었다.
Full Text Index의 경우 다양한 한글 지원기능을 구현하기 위해서는 코드 구현량이 많아진다는 문제점이 있었다. 또한 검색에 대한 통계를 시각화 하기위해서도 부가적인 코드가 발생한다. 그러므로 Elasticsearch의 Analyzer와 한글 Plugin 을 사용하고 Kibana를 이용하는것이 더욱 적합하다고 판단되어 도입하였다.
Elasticsearch를 도입하여 검색 기능을 수행하였을때, 간단한 검색에 대해서는 명확한 결과를 얻을 수 있었다 하지만, 짧은 단어를 검색하게 되면 Nori 형태소 분석기의 세세한 토큰화로 인하여 불필요한 조사가 검색결과에 포함되어 사용자가 의도하지 않은 결과가 검색되는 문제점이 존재하였다.
이를 해결하기 위해, 정보를 검색하게 되었고 Filter 를 적용하여 토큰화를 조정할 수 있다는 것을 알게되었다. 그래서 일반적으로 정보 습득을 위한 검색에서는 명사를 대상으로 검색을 수행한다는 점에 주목해 해당 방식으로 수정하였다.
- 기존의 MySQL 사용 방식 문제점
- Like 문을 사용하여 Detail 한 검색 기능을 사용하기 위한 부가적인 코드가 다수 발생
- Keyword 를 사용한 검색을 하기 위해선 관계 테이블 검색을 1회 더 수행해야 함
- 한글 관련 부가 기능을 제공하기 위해 부가적인 코드 발생
- 실시간 인기 검색어를 작성하기 위해 관련 테이블 증가
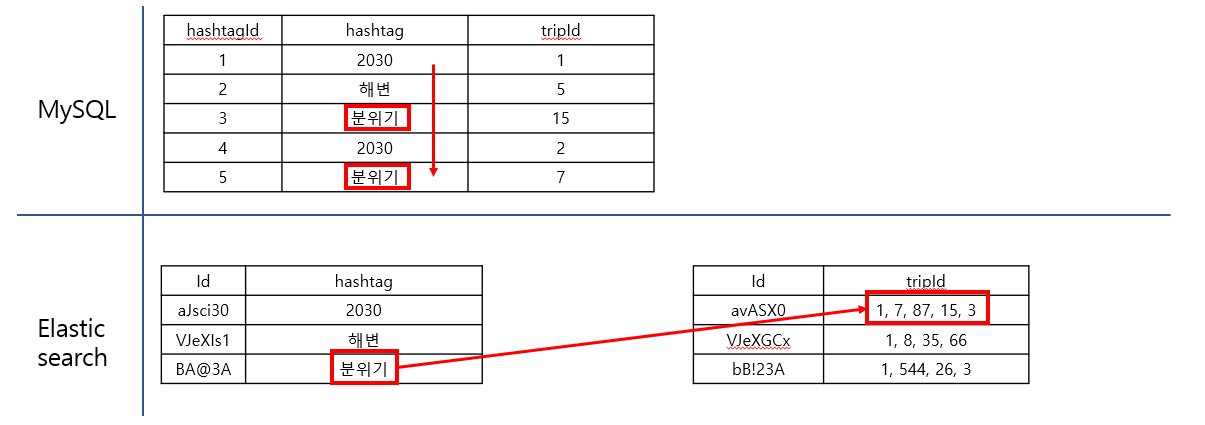
- 해결 방법
- Elasticsearch 도입
- Spring Data Elasticserach 도입
- 검색 성능 개선 결과
2. 검색 로그 기능 추가
주간 인기 검색어 기능을 구현하기 위해서 Elasticsearch 를 이용한 log 저장 기능을 구현하였다. 검색 기록을 log로 기록해두었다가 특정 시기에 모아 batch를 이용하여 업데이트하는 방식이 있지만, 현제 서비스 규모에서는 의미 있는 검색만 기록하고 호출한다면 크게 속도 저하가 발생하지 않는다고 판단되었다.
그래서 검색 결과가 있는 경우에만, Elasticsearch에 log 기록을 하였고 Kibana를 연동하여, 실시간으로 모니터링하고 요청 수가 많이 늘어나는 경우에는 리펙토링을 진행하기로 결정하였다.
- 인기 검색어 기능을 구현하기 위해 검색 로그 기능 필요
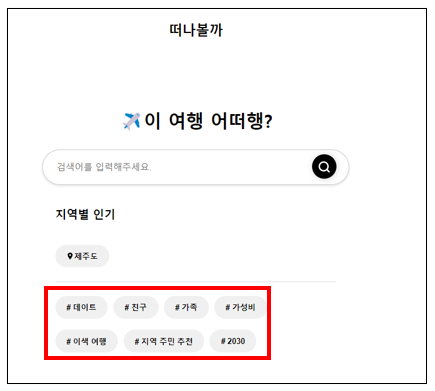
- 특정 조건을 달성 했을 때, 로그 저장
- 검색 결과가 있을 때, 로그 기록
- 인기 지역의 경우 자율성을 너무 주면 중복 데이터 발생 가능하므로 매핑해서 처리
EX > 서울, 서울특별시, 서울시 - 다 같은 의미

- 로그 기능 추가 결과
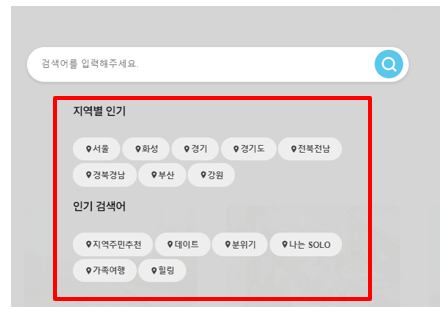
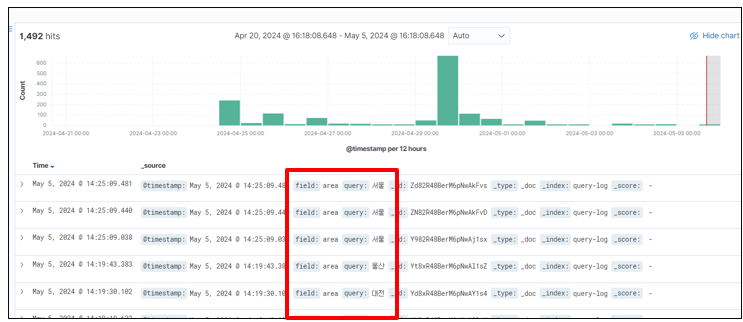
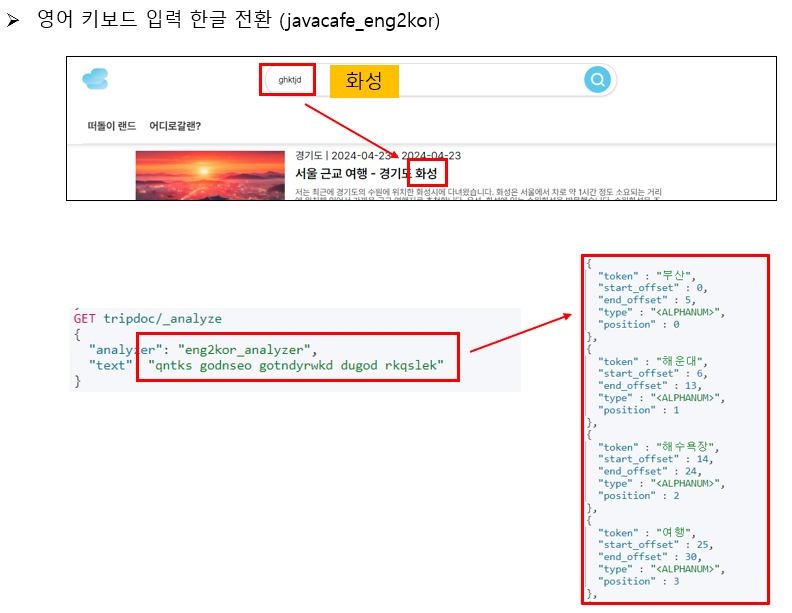
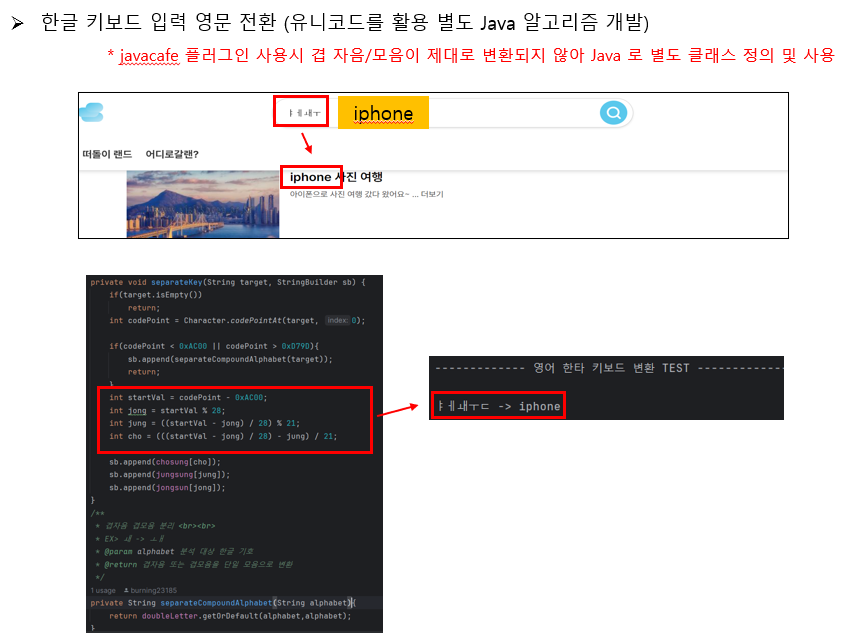
3. 한글 관련 추가 검색 기능 추가
한글 검색 관련 추가 편의기능을 제공하기 위해 Elasticsearchㄹ 이용한 방법에 대해서 조사하였다. javacafe plugin을 사용한다면 초성검색기능, 영타 한글 전환 제안, 한타 영문 전환 제안 기능을 간단하게 구현할 수 있다는 것을 알게되었다. 그래서 javacafe plugin 을 설치를 시도하였고 그 과정에서 version 호환성 문제를 발견하게 되었다.
Elasticsearch 7 버전 부터 다양한 기능과 성능 개선이 있었다는 공식 문서를 확인하여 7.11.1 버전으로 설치를 진행하였는데 javacafe plugin 은 Elasticsearch 6.X 버전까지 지원하여 설치가 되지 않았다. 그래서 설정 파일을 수정하여 7.11.1 에 맞추었지만 여전히 코드 내에 구조가 서로 달라서 설치가 되지 않았다.
에러 로그를 분석한 결과 특정 클래스에서 extends 를 하는 부분이 있었는데 7 버전 부터는 extends 없이 사용할 수 있다는 것을 알게되었고, 해당 부분을 수정하여 java 1.8 버전으로 컴파일한 후 적용하였다.
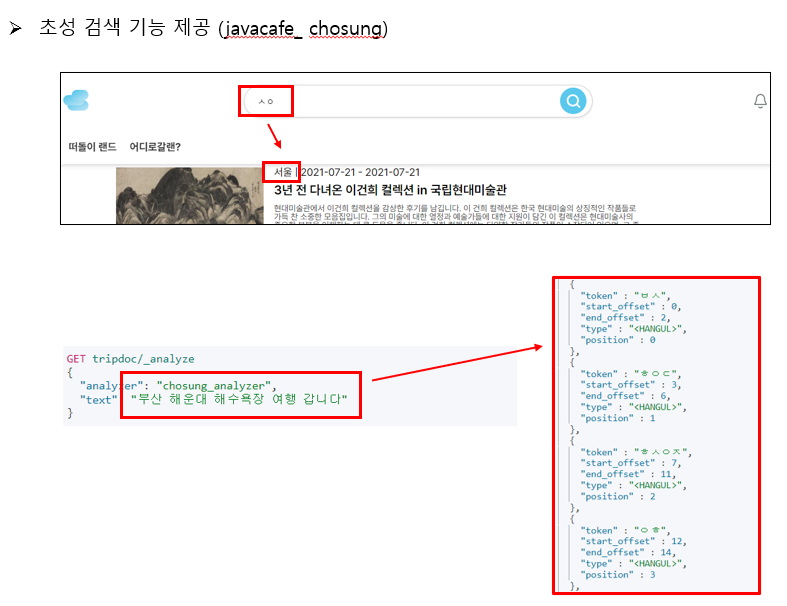
✅ Challenge
✓ 사용자 추천 알고리즘 구현
사용자에게 더욱 흥미로운 컨텐츠를 제공하기 위해서 사용자 추천 기능을 구상하였다. 추천 알고리즘에 대해서 조사를 진행하였고 Spark 와 mahout 을 이용하는 방식이 많이 소개되어 있었다. 이 방법은 코사인 유사도를 이용하는 방식 이었는데 고 유사도가 높은 단어를 수치화 하고 이를 연산하여 추천하는 방식이었다.
이 방식은 현제 서비스 규모에 적합하지 않는다고 판단되었고, Spark는 추가적인 인프라를 구성해야 한다는 문제점이 있었다. 그래서 또 다른 추천 방식에 대해서 검색하였고 장바구니 추천 (apriori) 알고리즘이 지금상황에 적합하다는 판단을 하게되었다.
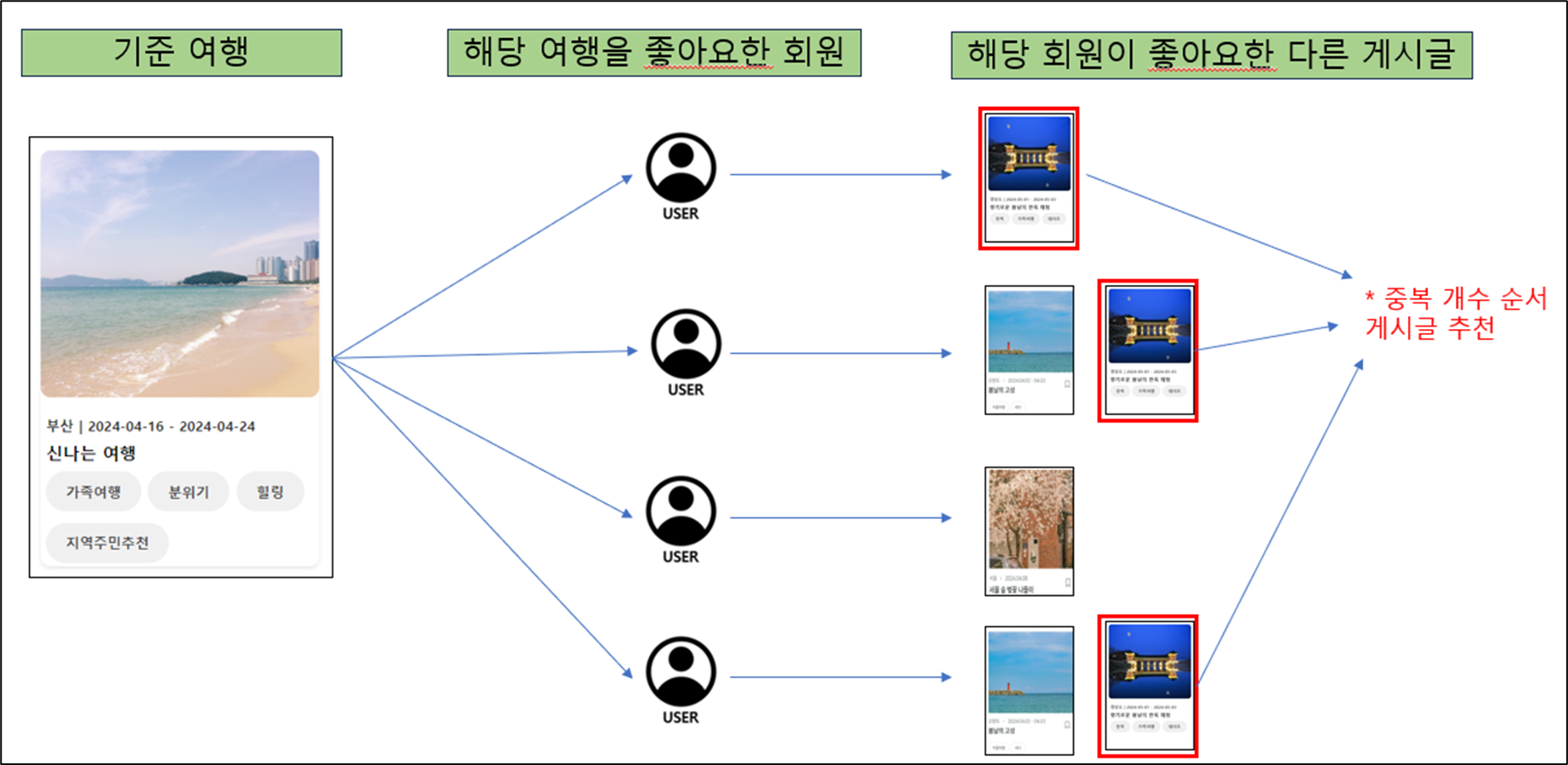
이 알고리즘을 간소화 하고 JAVA를 이용하여 알고리즘을 적용하는 방식을 채택하게 되었다. 기준글에 대한 좋아요를 누른 유저들이 공통적으로 좋아요를 누른 게시글이면 비슷한 취향의 게시글이 추천되지 않을까 라는 생각을 하게되었고 이를 장바구니 추천 알고리즘과 유사한 방식으로 구현하였다.
하지만, 이 방식은 새글이 등록된 경우나 좋아요가 충분하지 않은 초창기 서비스에는 추천 알고리즘을 사용할 수 없다는 문제점이 있었다. 이를 해결하기 위해서 컨텐츠 기반의 유사도 순으로 추천 게시글을 뽑는 방식을 채택하게 되었다. 이미 Elasicsearch를 사용하고 있었기 때문에, BM25알고리즘을 활용하면 추가 인프라가 필요없다는 장점이 있기 때문이다.
그래서, 해당 방식으로 TEST를 진행하였고, 게시글의 추천이 예상보다 많이 되지 않는다는 점을 발견하였다. 게시글의 내용과 같은 경우에는 대화체를 사용하고 있었고, 단순 명사로만은 유사한 글을 추천하기에는 어려움이 있었다. 그래서 OKT 형태소 분석기를 도입하여 대화체 교정, 사용자 사전 정의 단어, 동사 및 형용사의 기본형을 추가로 토큰화 하여서 유사한 게시글을 추천하도록 알고리즘을 구현하였다.
1. 좋아요 기반 추천 알고리즘
2. 게시글 내용 기반 추천 알고리즘 (좋아요가 충분하지 않는 경우나 새 글이 작성된 경우)
- 기존에 사용하던 Nori 형태소 분석기를 사용할 경우 문제점
- Formal 한 문장의 경우 효과적이지만 자연어에는 잘못된 분석을 하는 경우가 많음
- 내용의 경우 대화체를 많이 사용하므로 분석의 오류가 많음
- 해결 방법
- OKT 형태소 분석기 사용하여 대화체에 대한 분석 강화
- Customize Filter 를 설정하여 분석의 정확성 높임

- OKT 분석기 및 customize Filter 적용 결과
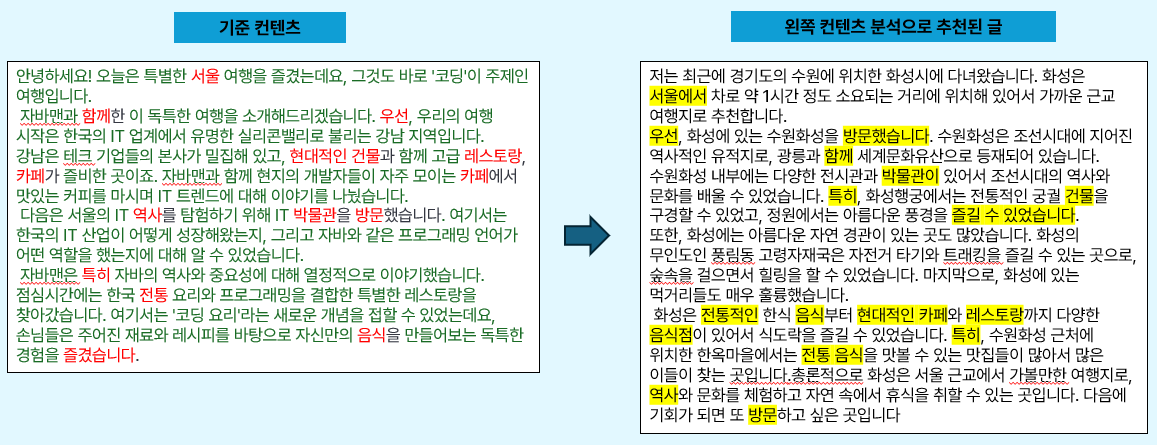
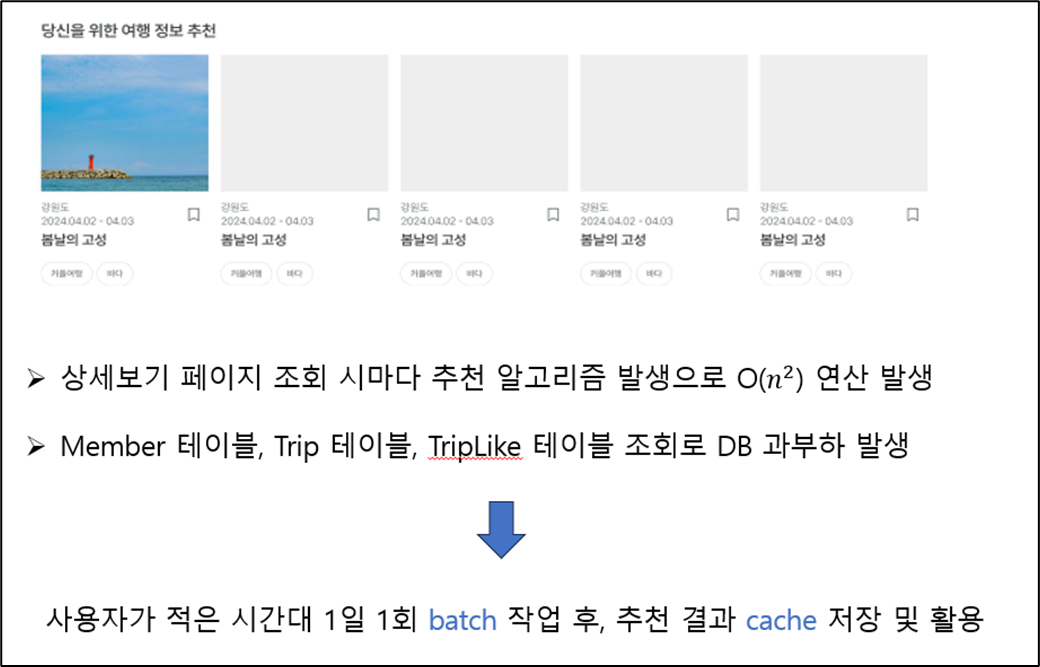
3. 추천 조회 기능 개선
앞서 말한 추천 알고리즘은 연산의 수행량이 많기 때문에, 게시글을 조회할 때마다 수행한다면 속도 저하가 발생할 것이라고 예상하였다. 그래서 batch 를 이용하여 사전에 집계를 수행하고 추천된 결과 게시글을 Cache 에 저장하고 활용하는 방식으로 문제를 해결하였다.
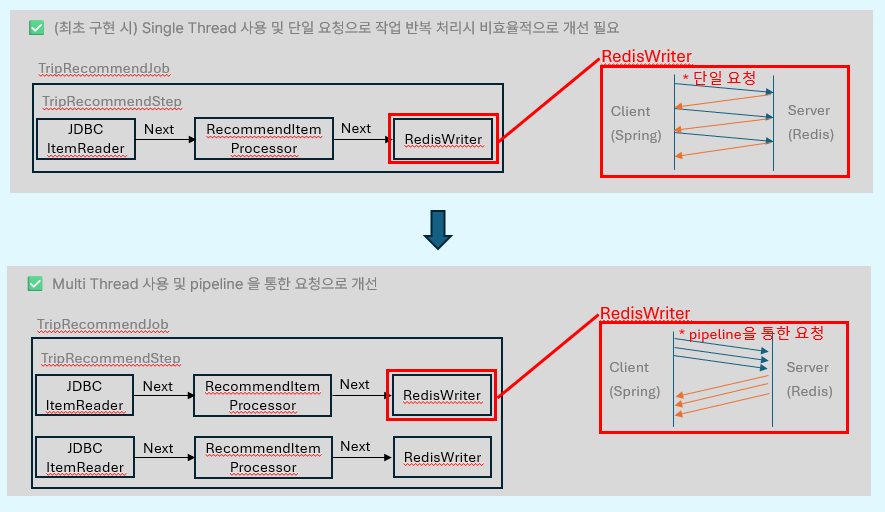
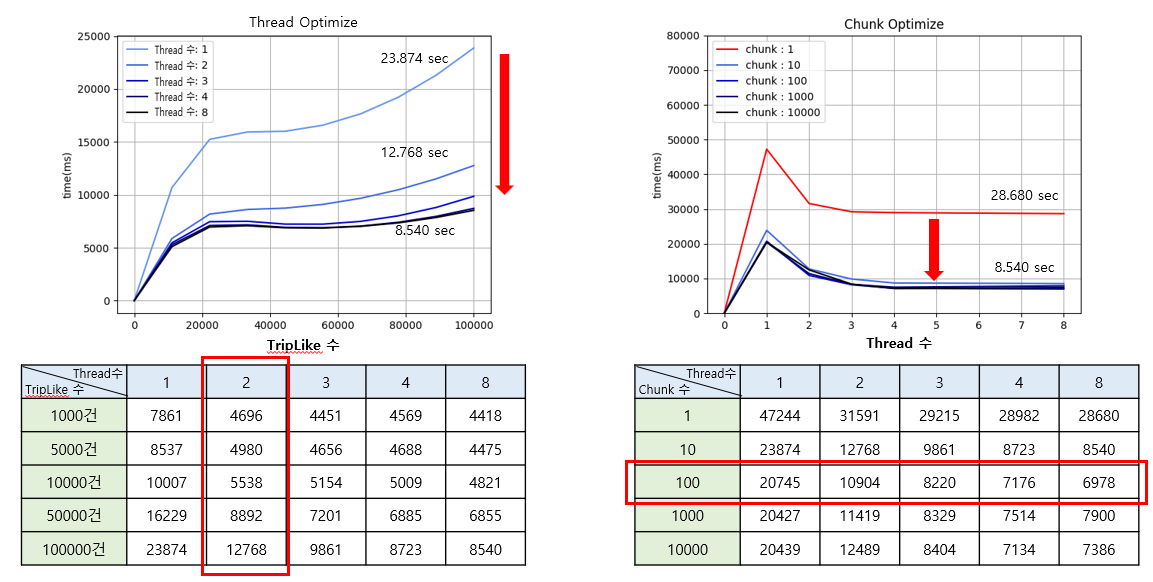
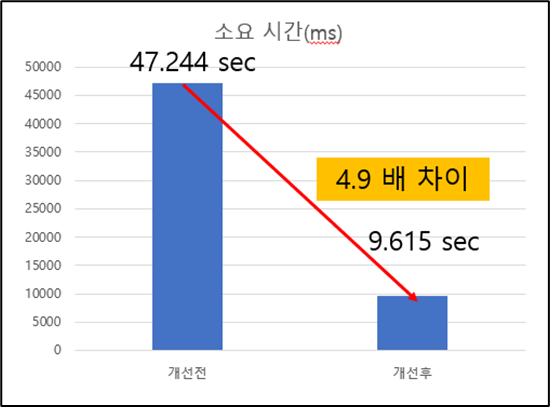
또한, Batch 수행 시간이 얼마나 걸리는지 TEST를 하였고 100만 게시글 기준으로 약 47초가 소요되었다. 이를 개선하기 위해 Chunk 기반 병렬 처리 구조와 Redis의 pipeline 을 이용한 요청으로 리펙토링을 하였다. 리펙토리 하는 과정에서 최적화된 Chunk의 수와 Thread 수를 결정하기 위해서 해당 인자를 변수로 두고 Test를 진행하였다.
Thread 수가 많으면 많을 수록 빠를 것이라는 단순한 예상을 하였지만, 게시글 100개 기준으로 2개를 초과 하면 도입한 자원대비 결과가 좋지 않다는 것을 발견하였다. 또한 Chunk의 수는 1개(Chunk의 수를 1로 두는것을 잘못된 설계)를 제외하고는 Chunk의 수와 수행 속도는 무관하다는 것도 알게되었다.
- batch 사용 조회 기능 개선
- 스케줄러(quartz) 를 사용하여 사용자의 사용이 적은 시간대 연산
- 연산 결과를 Cache (Redis) 에 저장 후 활용
- batch 구조 개선
- batch 설정 최적화
- Data를 증가시키며 Thread 갯수 별 처리 속도 비교로 최적 Thread 수 선정
- Data 수는 일정하게 유지하며, Chunk 별 처리 속도 비교로 최적 Chunk 갯수 선정 (결론: chunk갯수와 속도는 큰 연관관계가 없음)
- batch 최적화 결과
✅ 사용자 Feedback
짧은 기간으로 인하여 1주간 기획 및 설계를 진행하고, 2주간 기능 구현 후 유저 피드백을 진행하게 되었다. UI 가 불편한 부분이 많이 존재한다는 의견과 검색 사용시 불편함이 존재한다는 피드백을 받았다. 또한 투표 기능이 어렵다는 의견이 존재하여 다시 한번 처음 서비스를 사용한다고 가정하고 해당하는 부분을 최대한 수정하였다.
불편한 UI 부분에는 다양한 기능을 버튼식으로 제공하여 사용자 편의성을 높였고, 투표 기능은 간단한 사용법을 별도로 작성해 팝업창으로 제공하였다. 본인이 맡은 검색 부분은 Nori 형태소 분석기를 커스터마이징 하여 명사와 형용사를 위주로 검색되게 하였고, 한타/영타 변환, 초성 검색 등 타 플랫폼에서 제공하는 기능을 추가로 구현하였다.
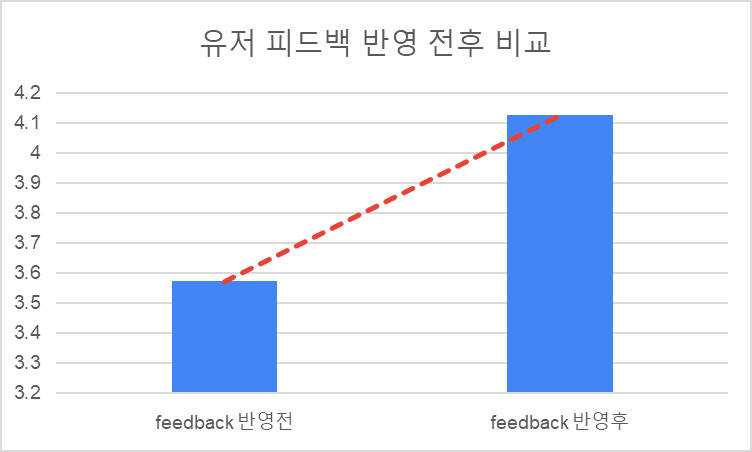
피드백 반영 결과 서비스 평점이 3.5 -> 4.2 로 약 10% 정도 상승하였다.
✅ 회고
짧은 기간 안에 실제로 사용할 수 있는 서비스를 만드는 것은 생각보다 어려웠지만 재미있는 경험이었다. 이전에는 Full Stack 개발로 브라우저의 데이터와 서버의 데이터를 직접 관리하였기 때문에 FE 개발자와 같이 협업에 필요한 요소들을 알지 못하였다. 하지만 이번 프로젝트로 Swagger 를 통한 문서화와 REST FUL 한 Api 설계, 내가 구현한 기능이 정확하게 어떻게 구현하는지 문서로 전달하는 것에 대해서 많은 고민을 해볼 수 있는 시간이었다.
또한, 진취적이고 책임감 있는 팀원들 덕분에 프로젝트에서 내가 맡은 부분에 완벽하게 몰입할 수 있었다. 서로가 맡은 부분을 정확하게 구현하고 마감 일정을 지켜준 덕분에 여러가지 성능 Test를 진행 해 볼 수 있었고, 서비스의 완성도를 더욱 높일 수 있었다. 또한, 힘겨운 일정 속에서도 항상 밝고 긍정적인 분위기를 만들어준 덕분에 BE 리더로서 더욱 완성도 높은 결과물을 만들 수 있도록 이끌어가는 원동력이 되었다.
조금의 기간이 더 있었더라면, 더욱 다양하고 재미있는 기능을 만들 수 있었을 것 같다는 아쉬움이 남지만... 좋은 동료들과 한정된 시간 안에 많은 것을 해볼 수 있었기 때문에 성공적인 프로젝트라고 생각한다.
'개발일지' 카테고리의 다른 글
| 개발일지 10주차 WIL (0) | 2024.04.07 |
|---|---|
| 개발일지 9주차 WIL (0) | 2024.03.31 |
| 개발일지 8주차 WIL (0) | 2024.03.24 |
| 개발일지 7주차 WIL (0) | 2024.03.17 |
| 개발일지 6주차 WIL (0) | 2024.03.10 |