- 중복되는 영단어 제거 정규식
"\\b(\\w+)(\\s+\\1\\b)+"- \b:
- 단어의 시작이나 끝 (단어의 경계)
- 공백, 구두점 등과 같은 비단어 문자와 단어 문자(영문자, 숫자 등) 를 구분 가능
- (\w+):
- 하나 이상의 단어 문자를 찾습니다.
- \w는 알파벳 대소문자, 숫자,밑줄(_)을 포함
- +는 하나 이상의 문자로 이루어진 패턴
- 이 부분은 그룹으로 지정 ( 그룹 1 )
- (\s+\1\b):
- \s+: 하나 이상의 공백 문자(스페이스, 탭 등) 찾기
- \1: 그룹 1 의 내용을 참조하는 역할
- \b: 단어 경계
전체적으로 작동하는 방식:
- 정규식은 먼저 단어 경계에서 시작하고, 그 다음에 단어 문자가 하나 이상 있는지를 확인합니다. 이 문자는 캡처 그룹 (\w+)에 저장
- 공백이 최소 하나 이상 있는지를 확인하고, 그 다음에 방금 캡처한 동일한 단어(\1)가 있는지 확인
- 동일한 단어 뒤에 단어 경계(\b)가 있어야 함(단어의 끝임을 확인).
* 경계는 중복 단어뒤 다른 단어와 연결되어 있지 않는지 확인
요약
- 일치하는 패턴 찾기 ( 입력 문자열에서 정규식 패턴이 일치하는 부분을 찾기 )
- 중복 단어로 교체 ( 패턴이 일치하는 경우, 이를 첫 번째 캡처 그룹(\1)으로 교체 )
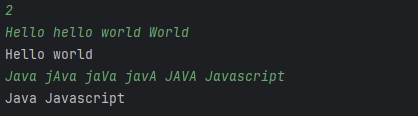
EX> "Hello Hello world" 입력
- \b(Hello)(\s+Hello\b) 패턴이 일치
- 첫 번째 단어인 Hello가 캡처
- 공백 후에 Hello가 다시 등장하므로 Hello 1 단어로 교체
- 결과: "Hello world"
- 영단어 대소문자 무시 적용
* 아래의 패턴을 추가로 적용
Pattern.CASE_INSENSITIVE
- 전체 코드
import java.util.Scanner;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Example {
public static void main(String[] args) {
Pattern p = Pattern.compile("\\b(\\w+)(\\s+\\1\\b)+", Pattern.CASE_INSENSITIVE);
Scanner in = new Scanner(System.in);
int t = Integer.parseInt(in.nextLine());
for(int i = 0 ; i < t ; i++){
String input = in.nextLine();
Matcher m = p.matcher(input);
while (m.find()) {
input = input.replaceAll(m.group(), m.group(1));
}
System.out.println(input);
}
in.close();
}
}
'JAVA > Regex' 카테고리의 다른 글
| [JAVA/Regex] 문자열 유효성 패턴 검증 (0) | 2024.10.24 |
|---|